本篇文章聊下MySQL索引。
索引使用来解决什么问题。
- 没有索引,那么查询数据,每次都是遍历查询全部的数据,那么如果数据量大的话,会慢的要死。所以索引创建出来的本质目的就是为了
解决查询慢的问题
MySQL支持哪些索引
- primary key 唯一索引,不允许为NULL
- Unique 唯一索引,允许为NULL
- Index 普通索引以及组合索引
- FullText 全文索引
MySQL支持哪些数据结构
- Hash
- B+
从无序数据结构VS有序数据结构的角度,聊下为啥MySQL索引是B+树
为什么这么多都可以优化索引,为什么MySQL选择了B+,我们从下面几个方面来解释下。
无序数据结构
数据结构是没有顺序的,所以一般就是KV等值查询,对范围查询支持性还是不行
Hash
简单讲Hash就是一个KV结构的数据结构。
- 优点
- 对于
等值查询查询速度会非常快
- 对于
- 缺点
- 对于KV结构的很明显支持不了非
等值查询的场景。
- 对于KV结构的很明显支持不了非
- 最佳适用场景: 对于需要等值查询的茶镜比如Redis、Memcached这些中间件使用Hash效果就会更好
有序数据结构
有序的数据结构有很多,基本的有序数组,二叉排序树,平衡二叉树,B树(B-树),B+树,红黑树。下面我们就逐个来解释下其优缺点.
有序数组
顾名思义,就是一个排好序的数组。
- 优点
- 其对于等值(二分或者其他的查找方式)或者是范围查询都可以很好的支持.
- 缺点
- 对于update类型操作(增删改)数据,会改变其原有数据结构,成本会有点高.
- 适用场景:缓存静态数据(不会被修改,或者是极少被修改的场景)
二叉排序树
二叉排序树数据结构分析,参见博客相关分析文章。
- 优点
- 有序,可以支持范围查找。对于等值查找时间复杂度最优是O(lgN) 最差是O(N)。
- 缺点
- 对于极端情况下如下图,层数就过于高了,所以就需要下面的平衡二叉树
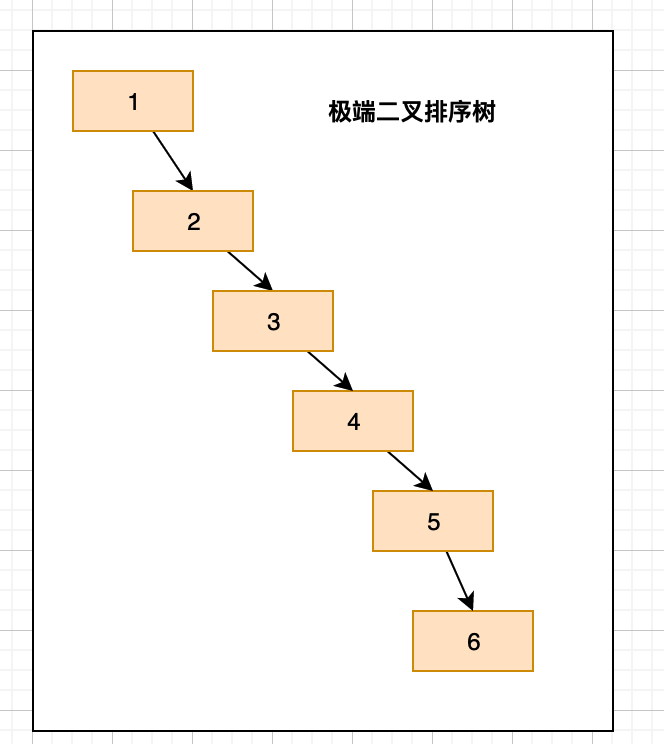
- 适用场景:范围查询支持度不是很好,一般场景都是用二叉排序树数的优化版本。
平衡二叉树
平衡二叉树简单讲就是讲二叉树极端lg(N)情况消除掉了
- 优点
- 有序,可以支持范围查找。对于等值查找时间复杂度稳定为O(lgN)。
- 缺点
- 因为是二叉树,如果数据节点过多,那么树就会特别高。如果有N个节点,那么层高就是lg2(N+1). 因为索引不一定是在内存中存储的,所以树越深,磁盘io越多,那么查询时间就长。
- 适用场景:平衡二叉树已经是一个很好的数据结构了。对于范围和等值查询等支持的都是很好。所以如果是数量量较少,使用内存就可以使用,建议是使用平衡二叉树。
B树
B树是平衡二叉树的进化版。主要是解决树过于深,导致磁盘io过多。简单理解B树就是平衡多叉树。B树中的非页节点保存数据。
- 优点
- 有序,在平衡二叉树的基础上,扩展为并不仅仅是二叉。从一定程度上降低了树的深度,减少io查询次数.
- 缺点
- 其实B树已经是很好了。如果硬要说缺点,就是查询效率没有B+树高.
- 适用场景: 大数据量,想要优化性能。 MongoDB索引使用的是B树。
B+树
B+树就是在B树的基础上,冗余了在非叶子节点冗余了索引数据,提高范围查询效率。
优点: 有序,在列举的数据结构中,查询效率较高,以及对磁盘io的次数较低。
缺点: 实现复杂。增删改查都需要很复杂的操作。大佬可以手撸代码。
B+树的节点中存储多少个元素最合适
- 为一页或者是页的倍数。因为不是页的倍数,磁盘io都是会造成资源的浪费。
页的概念
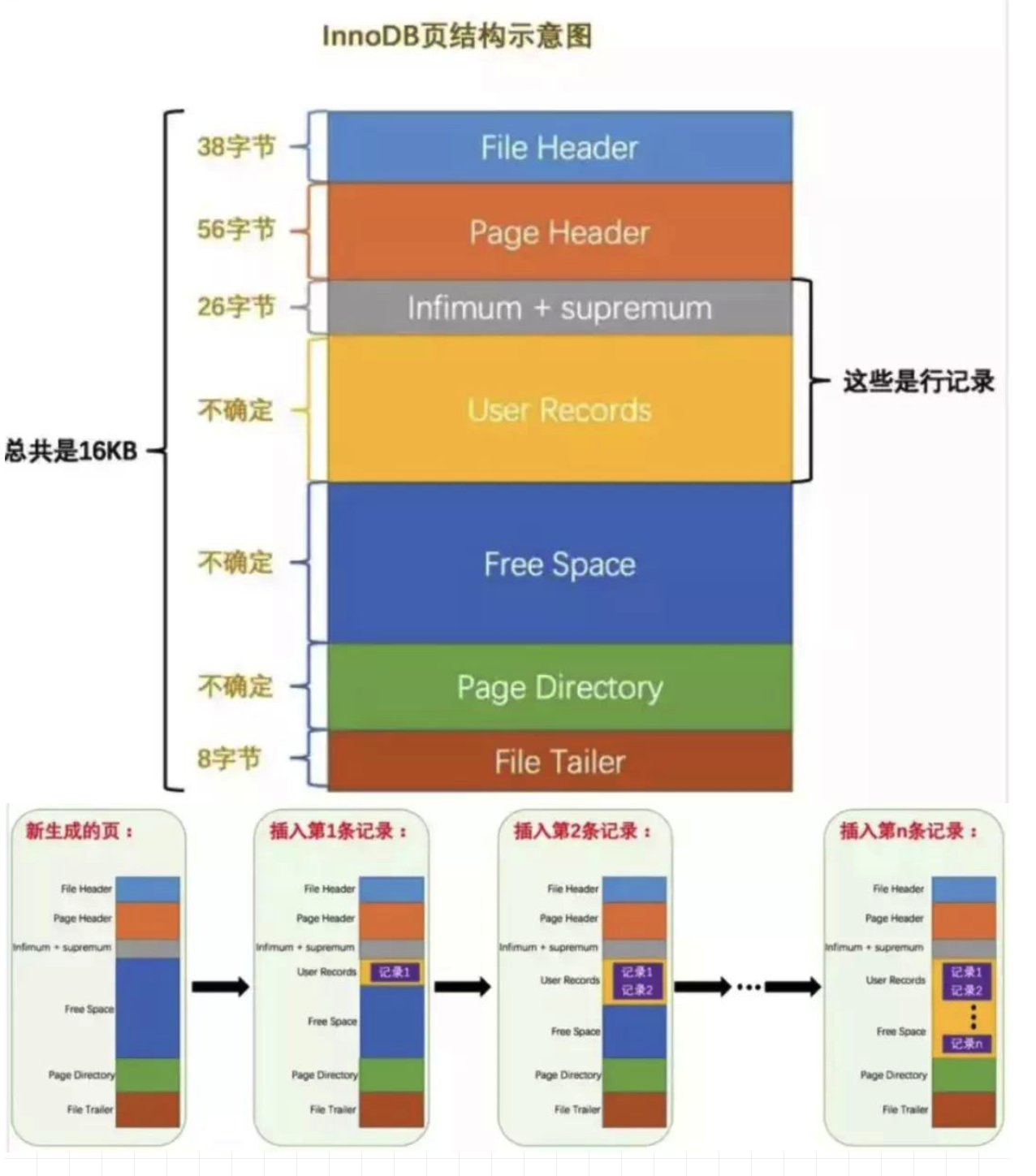
- 数据页之间是双向链表
- 数据页内的数据记录之间是单向链表
- 每个数据页都会在有一部分空间用来存储页目录。通过主键查找记录的时候,可以在页目录中使用二分快速定位对应的记录槽,然后在槽里面找到对应的记录。
- 一次查询过程
覆盖索引
其实就是某个索引已经包含了要查 的数据,所以就没有必要找到实际的记录。比如根据索引name 查找主键id。那么索引那么已经包含了id,就没有必要再继续查询了。
最左匹配原则
- 索引可以指定1列(a), 也可以指定多个列(a,b,c,d)即联合索引
- 如果是联合索引,索引只能用于查找key是否存在(相等),遇到范围查询(> < between like)等就不能进一步匹配,会后退为线性查找。
- 例子: 如果有索引(a,b,c) 查询SQL
select * from tabl a=1 and b>2 and c > 3. 则会在每个节点依次命中a,b 无法命中c. 因为b已经是范围查询了, c就更不会排序查找了。
- 例子: 如果有索引(a,b,c) 查询SQL
总结
- 索引是为了查找速度快而出来的。如果快速定位到对应的记录,或者是根据索引能够筛选出一大部分非目标记录,这就是优化查询的本质。