本篇我们聊聊HashMap && ConcurrentHashMap.
HashMap
我们从下面几个角度来剖析下jdk1.8的HashMap
- HashMap 的存储结构
- HashMap的构造器
- HashMap的put方法
- HashMap的get方法
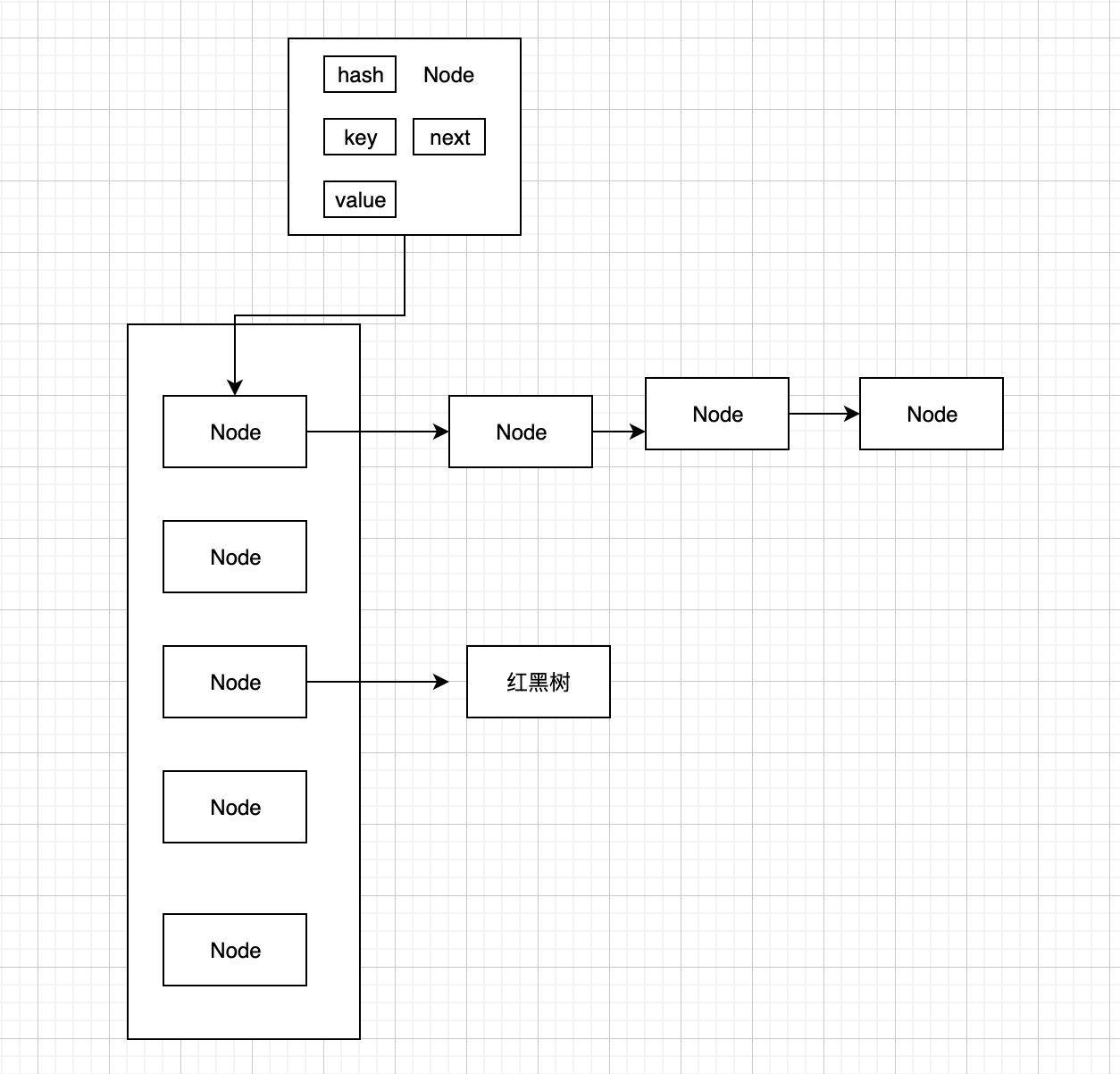
HashMap 的存储结构
- 如果冲突数是小于阈值(默认是8) 则是数组+链表
- 如果冲突数是大于阈值(默认是8) 则是数组+红黑树
- 具体见下图
HashMap的构造器
1 | // 初始化size. 并且制定需要resize的阈值 |
HashMap的put方法
- 需要注意的是jdk1.8中引入了红黑树,本篇对红黑树不多讲,如果需要知道详细的请自行google
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158// 对外
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 这个方法是优化
// 1 h>>> 16 表示高位也参与了计算,减小碰撞率
// 2 (n-1)&hash == hash%n &比%计算的快
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 插入新节点,replace 原有的value,resize, 链表转红黑树
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果table 为null, 或者是tab的长度为0,就需要进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 扩容 resize
// 如果对应的节点值为Null 则表示没有碰撞,直接创建一个新的node
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 表示有碰撞了
Node<K,V> e; K k;
// 这个表示 key是一样的
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果key 不一样 并且是TreeNode 就需要红黑树插入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// key不一样,并且不是树节点,就表示是链表了。需要将节点追加到链表的尾部(如果超过阈值(默认8),就需要转成红黑树)
for (int binCount = 0; ; ++binCount) {
// 如果同样key 的Node 没有下一个Node. 则直接追加一个新的Node
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 是否超过红黑树的阈值
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 这里表示下一个节点的key与要插入的key是一样的
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 继续下一个Node
p = e;
}
}
// e不为null 则表示有同样key的Node存在
if (e != null) { // existing mapping for key
V oldValue = e.value;
// onlyIfAbsent->为false 或者原来的value为null. 则表示需要替换掉原来的值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 额外的接口,访问完之后回调
afterNodeAccess(e);
return oldValue;
}
}
// 到这里 就表示没有key一样,并且已经Put了
++modCount;
// 更新size
if (++size > threshold)
resize();
// 插入成功之后回调
afterNodeInsertion(evict);
return null;
}
// 扩容
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 如果原有table不为空
if (oldCap > 0) {
// 原有table 大于最大的数组,不用扩容了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 这里就是扩容一倍, 设置新的上限
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 原有为空,则查看阈值是否大于0
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr; // 默认值,或者是指定的值
else { // 到这里 其实就是 原来数组没有值,并且threshold也小于等于0,就直接给默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// newThr(前面初始化为0) 为0,则需要重新计算下上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 截止到这里,扩容已经完成了,下面就是讲原来的数据全部重新计算下hash
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果没有下一个节点,直接赋值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果下一个节点是红黑树,进行红黑树的操作
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 链表
// 下面操作的逻辑是,因为是扩容了2倍,所以将原来链表上的数据根据新的hash值,拆分成高位的(j+oldCap)&低位的(j) 两个链表
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 返回扩容后的先的tab
return newTab;
}
HashMap的get方法
1 | public V get(Object key) { |
HashMap 线程不安全问题
- jdk1.7 是存在多线程操作resize 死循环(这里简单提一下死循环的原因: resize的是时候链表会倒序。多个线程就会导致A->B->A.)
- jdk1.8虽然已经修复了死循环问题,但是没有加任何额外的同步操作,还是存在线程不安全。
- 存在数据丢失。
- 多线程时,如果线程A resize 了, hash结果为AHash, 线程B持有原有的threshold, 并且计算出来的hash也是AHash, 则直接覆盖掉对应的链表头。就会导致数据丢失。
- 存在数据丢失。
线程安全的Map
- 前面聊到HashMap 不是线程安全的,在java中线程安全的Map有下面几个
- Hashtable & SynchronizedMap
- 方法使用synchronized 修饰。 效率偏低
- ConcurrentHashMap
- 采用分段锁的概念,效率比Hashtable 高很多
- Hashtable & SynchronizedMap
ConcurrentHashMap
我们从下面几个角度来剖析下jdk1.8的HashMap
- ConcurrentHashMap 的存储结构
- ConcurrentHashMap的构造器
- ConcurrentHashMap的put方法
- ConcurrentHashMap的get方法
前言
- ConcurrentHashMap jdk1.5-jdk1.7 都是使用的分段锁的概念来保证线程安全,以及性能。
- jdk1.8不一样的点在于
- 抛弃了原来分段锁的概念,使用CAS+synchronized 进行更细粒度的扩容与更新。
- 增加ForwardNode 来标识Node已经被移动,多线程并发
- 使用3个CAS保证的更新查找的原子性
- sizeCtl不同值代表不同的操作
- 使用synchronized 替换ReentrantLock
ConcurrentHashMap 的存储结构
- 存储结构与HashMap是一样的,不过是采用CAS+Synchronized 保证线程安全
ConcurrentHashMap的构造器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
// 下面是一些关键性的属性
/* ---------------- Fields -------------- */
/**
* table Hash表
*/
transient volatile Node<K,V>[] table;
/**
* 扩容的时候使用。只有在扩容的时候是非空的
*/
private transient volatile Node<K,V>[] nextTable;
/**
* 保存的是hashmap 中的数目,使用CAS更新。
*/
private transient volatile long baseCount;
/**
* 有下面几个作用:
* 1 sizeCtl 为负数时,-1标识正在初始化。-N标识正在有N-1个线程在进行扩容操作
* 2 sizeCtl 为正数是。
* - 如果数组为Null 则表示是在初始化过程中,sizeCtl 为新建数组的长度。
* - 如果已经初始化了,则表示当前数据容器(table数组)的临界值. (临界值=数组的长度*loadFactor)
* 3 sizeCtl为0 则表示数组长度为默认值(16)
*/
private transient volatile int sizeCtl;
/**
* The next table index (plus one) to split while resizing.
* 扩容中下一个需要操作的节点。
*/
private transient volatile int transferIndex;
/**
* Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
*/
private transient volatile int cellsBusy;
/**
* Table of counter cells. When non-null, size is a power of 2.
*/
private transient volatile CounterCell[] counterCells;
// views
private transient KeySetView<K,V> keySet;
private transient ValuesView<K,V> values;
private transient EntrySetView<K,V> entrySet;
/**
*
* 默认table size = DEFAULT_CAPACITY(16)
*/
public ConcurrentHashMap() {
}
/**
初始化 table size. 注意这里的sizeCtl
*/
public ConcurrentHashMap(int initialCapacity) {
// 如果初始化的长度小于0
if (initialCapacity < 0)
throw new IllegalArgumentException();
// 超过了最大值就是最大值,否则就是最近的2次幂(具体可看hashmap)
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
// 只是长度,还没有开始构建table. put的时候才会构建
this.sizeCtl = cap;
}
/**
* Creates a new map with the same mappings as the given map.
*
* @param m the map
*/
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
/**
// 具体看下面的构造方法
*/
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
/**
指定,初始化的table size。 以及扩容阈值。
concurrencyLevel 我理解是支持并发的节点数。 因为jdk1.8是每个Node作为一个端,所以如果初始化的节点小于并发节点数,就设置为并发的节点数
*/
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
ConcurrentHashMap的put方法
- 增加/更新数据
- 链表->红黑树
- 扩容
- size更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 如果key 或者value为null 则直接报错
if (key == null || value == null) throw new NullPointerException();
// rehash 类似HashMap中的Hash
int hash = spread(key.hashCode());
int binCount = 0;
// 注意这里是一个死循环
// 终止的条件是put成功之后才会跳出去
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果table 为null 那么需要初始化表
if (tab == null || (n = tab.length) == 0)
tab = initTable(); // 初始化
// table 不为空, 且对应位置没有冲突
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 直接更新到对应的节点
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f); // 多线程扩容
// table 不为 null && 且不在扩容,且有冲突
else {
V oldVal = null;
// 锁
synchronized (f) {
// 这里为什么还会再判断一次,是因为其他线程可能改了对应的Node
if (tabAt(tab, i) == f) {
// fh 是Node 的节点Hash值,fh不为0 则表示是链表
if (fh >= 0) {
binCount = 1;
// 下面的操作是:1 如果存在key一样的,则根据onlyIfAbsent 更新,或者是放弃更新
2 如果不存在key一样的,则在链表尾部追加
// 注意这里的binCount.只有链表才会自增(为下面treeifyBin做数量判断)
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果是树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 则更新红黑树
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// binCount 标识更新了,注意这里没有synchronized 修饰。 但是里面真正调整,还是有用到synchronized 修饰的
if (binCount != 0) {
// binCount 如果是红黑树,则一直是2
// 如果小于TREEIFY_THRESHOLD,则需要将链表转换成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
// oldVal不为null 则表示有相同的key
if (oldVal != null)
return oldVal;
break;
}
}
}
// 修改当前的数量,并且检查是否需要扩容
addCount(1L, binCount);
return null;
}
// CAS 查询对应节点
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
// CAS 比较并且set
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
// CAS 无比较 直接set
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
/**
* Helps transfer if a resize is in progress.
*/
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
/**
* 修改当前的baseCount, 提供是否需要扩容标识
*/
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
// 如果需要检查
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
// s >= sizeCtl 则表示是需要扩容的
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
// sc 小于0 则表示需要扩容或者是扩容中
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
// 扩容
transfer(tab, nt);
}
// sc 大于等于0 就表示是第一个或者唯一一个发起扩容的线程。
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
ConcurrentHashMap的transfer方法
- 主要分为两部分
- 一个是先扩容一个nextTable 长度为2倍的当前节点
- 第二个部分就是讲原来tab中的数据迁移到新的Table中。
- 这里更新是多线程的。如何是多线程呢?
- 这里注意一个ForwardNode。ForwardNode 是一个集成Node的子类,但是实际上只有next 会有值(第一部分的nextTable).
- 操作流程(具体可以看代码注释,这里只是简单总结下是如何做到多线程更新的)
- 具体来讲就是如果在扩容中,这个时候回更新整个tab 到新的nextTable.
- 从前到后依次调整,如果已经操作过了节点 将ForwardNode 放置在Node上,如果其他节点查询到该节点是ForwardNode,那么就会调用helpTransfer(). 这样子就是多线程帮忙迁移了
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
ConcurrentHashMap的get方法
1 | public V get(Object key) { |
参考大佬
JDK1.8 HashMap源码分析
并发容器之ConcurrentHashMap详解(JDK1.8版本)与源码分析
【Java并发】– ConcurrentHashMap如何实现高效地线程安全(jdk1.8)