本篇详细聊聊Jvm 虚拟机栈,堆,以及GC
本文基于jdk1.8
- 虚拟机栈 VS 堆
- 栈管运行,堆管内存 (这个不一定全部,但是一定程度上也说明了栈堆的区别)
虚拟机栈 (VM Stack)
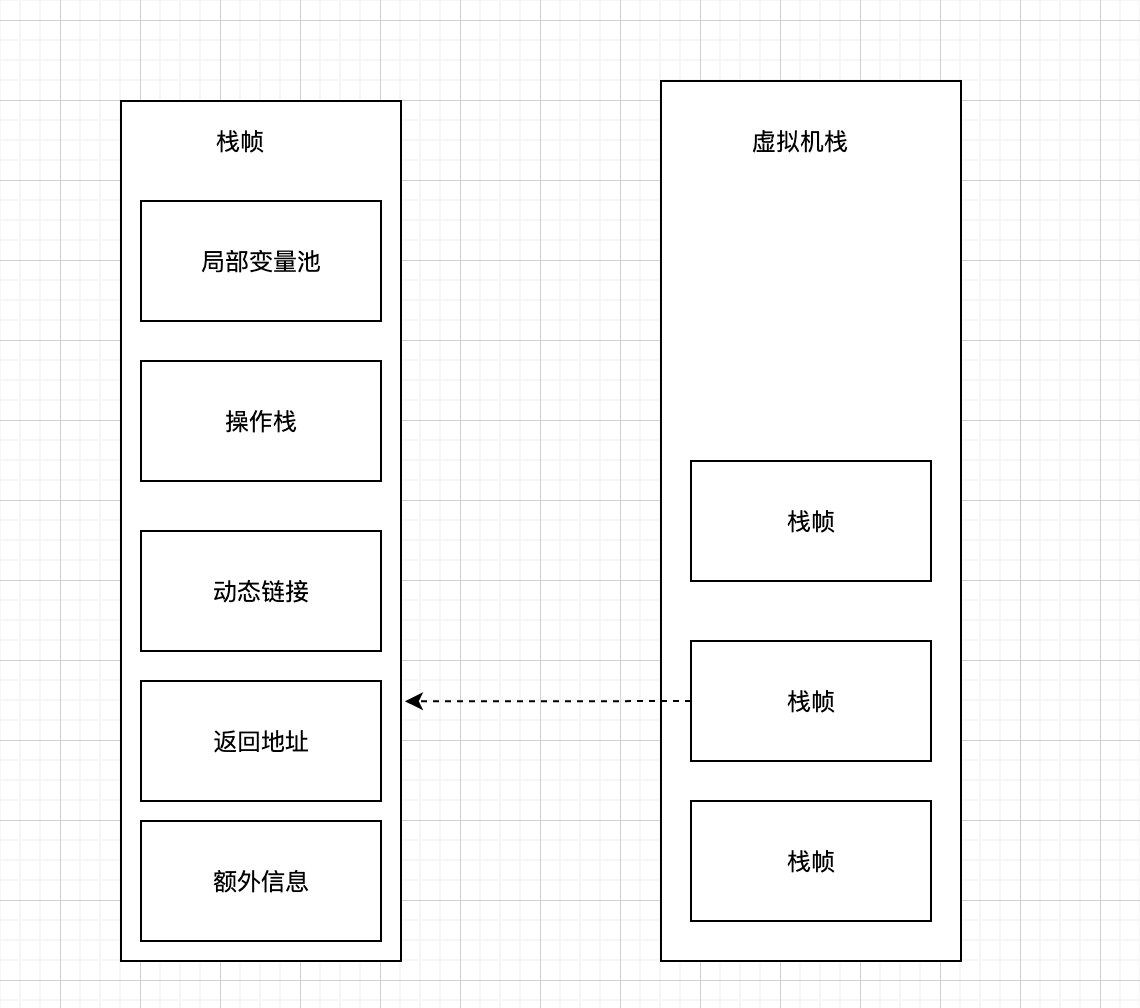
先放一张结构图
虚拟机栈属于非共享区域
每个线程都有一个自己的栈空间
- 可以通过-Xss20m(将栈空间设置成最大为20m)
栈的主要构成就是栈帧。一个方法的调用就是一个栈帧。
栈帧的里面的内容主要包括
- 局部变量表
- 编译的时候就已经确定了,这里涉及的内容不会改变
- 操作栈
- 简单理解就是一个方法里面的代码逻辑 也是基于栈来的。(更细维度的栈)
- 描述的是方法的具体执行
- 动态链接
- 简单理解就是对于对象,栈帧只保存其引用。其具体所在位置在堆中。
- 方法返回地址
- 方法退出有两种:
- 正常退出。如果有返回结果,则会把结果压入到上一个栈帧的操作栈中
- 异常退出。抛异常,由上层栈帧做异常处理
- 方法退出有两种:
- 额外信息
- 局部变量表
因为在栈帧内存储的是局部变量,操作栈,动态链接都是在编译是确定的,所以一个栈帧的大小是固定的。
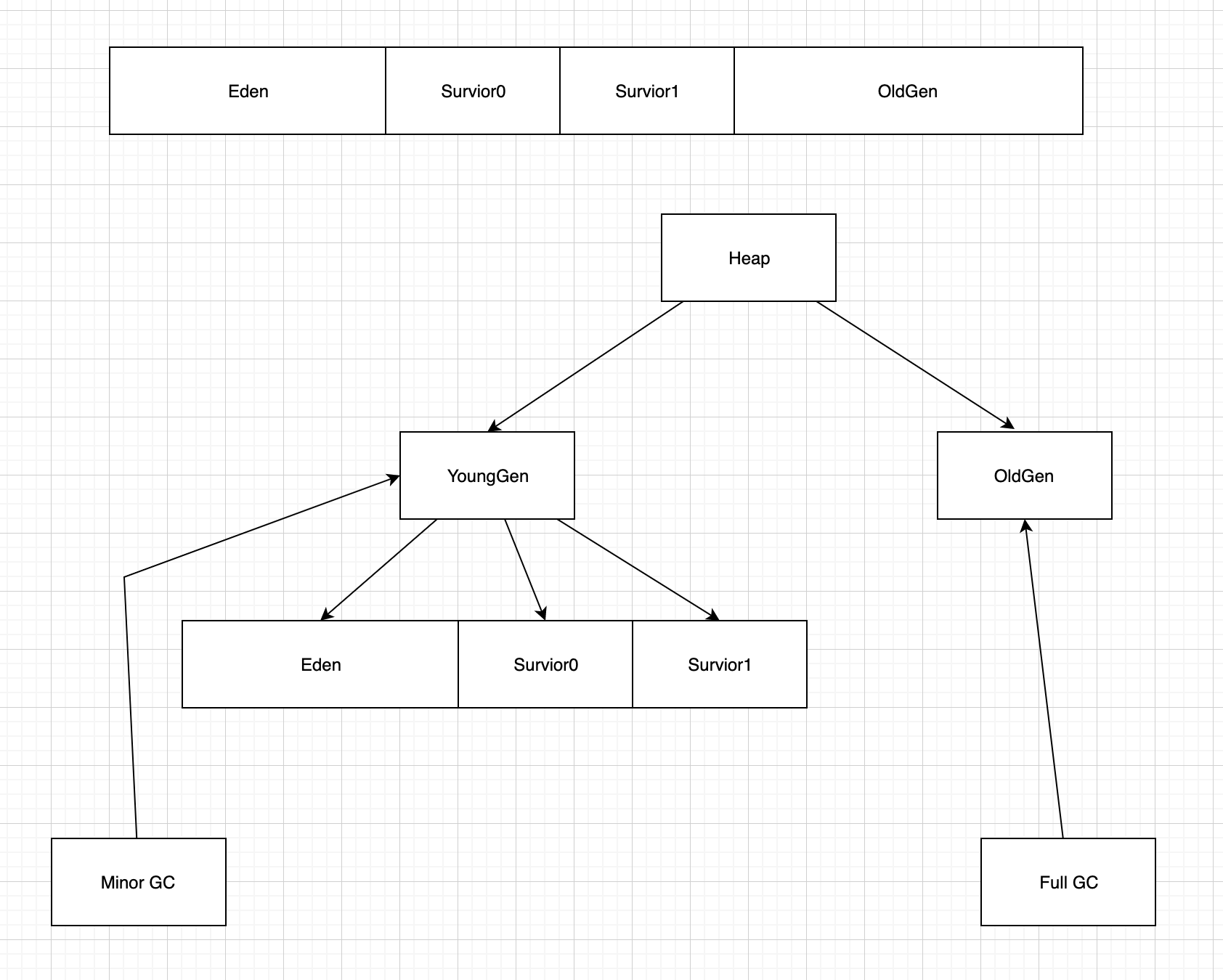
堆 (Heap)
- 主要存放各种实例对象
- 具体抽象结构如下
- 分区
- Young
- Eden + survivor0+survivor1 (默认比例8:1:1)
- 使用的是复制GC(minor GC), 每次总有一块Survivor 是空闲的。 90%可使用
- Old
- minorGC超过(15次)存活的对象,或者是超大对象
- FullGC.
- Young
GC(垃圾回收) Garbage Collection
先聊下那些需要被回收
虚拟机栈,程序计数器,本地方法栈。这三个都是随线程而生,随线程而灭, 所以不需要考虑过多考虑回收- 堆与方法区
复制 (Copying)
- 将内存分为两块(A,B),平时只用一块A。GC的时候,将使用的一块A中GCROOTS可以查到的对象紧密复制到另一块B,然后将之前板块A全部清空。
- 优点:效率高
- 弊端:内存只能用一半
标记整理 (Mark-Compact)
- 过程
- 标记: 先通过GCROOTS到达的对象,
- 整理:移动所有标记存活的对象,重新排列。然后将内存地址值之后的内存清空
- 优点:内存使用率高,无内存碎片
- 弊端:需要暂停程序, 效率交Copying慢
标记清除 (Mark-Sweep)
- 过程
- 标记: 先通过GCROOTS到达的对象,
- 清除:清楚未被标记的对象。
- 优点:内存使用率高。
- 缺点:
- 会产生内存碎片,逐渐的连续的可用空间越来越小,导致gc越来越频繁
- 需要暂停程序
分代收集
- 新生代(copying)
- 老年代(标记整理/标记清除)
垃圾回收器
jdk8 默认的是Parallel Scavenge + ParallelOld
Serial(串行收集器)
- 单线程 stop the world
- 复制算法
ParNew(Serial的多线程版本)
- 复制算法
Parallel Scavenge
- 并行多线程收集器
- 复制算法
- 有自调节
SerialOld
- 串行老年代版本
- 标记/整理算法
ParallelOld
- 并行老年代版本
- 标记/整理算法
CMS
- 以最短回收停顿时间为目标,使用标记-清除算法
- 过程:
- 初始标记:stop the world 标记GC Roots能直接关联到的对象
- 并发标记:进行GC Roots Tracing
- 重新标记:stop the world;修正并发标记期间因用户程序继续运作而导致标记产生变动的 那一部分对象的标记记录
- 并发清除:清除对象
- 优点:并发收集,低停顿
- 缺点:
- 对CPU资源敏感
- 无法处理浮动垃圾(并发清除 时,用户线程仍在运行,此时产生的垃圾为浮动垃圾)
- 产生大量的空间碎片
G1
- 并行与并发
- 分代收集
- 面向服务端应用,将整个堆分为大小相同的region
JVM 一些调优参数
- -Xms512m (堆初始大小)
- -Xmx1024m(堆最大大小)
- -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=1024m. 调整元空间大小(存储java类信息)
- -Xss128m (虚拟机栈大小)
- -XX:NewRatio=4 (young:old=1:4) 默认是2