高并发是工程师老生常谈的事情。高并发简单来讲就是是服务器端,能够及时响应每秒成千上万次的请求,并且没有任何异常。博主根据自身的工作经历,在接下来的几篇文章中,从矛(爬虫)以及盾(服务端开发)两个方面来聊聊高并发。本篇是主要聊矛
先瞎聊几句
- 关于爬虫(网络爬虫)相关的一些概念,请读者自行google。
- 爬虫的主要功能:本质上还是数据采集。
- 本篇文章只是博主的个人见解,仅供参考。大家还是要做个盾法的公民,违法后果自负。
一些前提
- 工具语言使用python(python中线程对于Io基本是单线程,所以考虑进程+协程)
- 假设网站服务端支持QPS是无限的(1s返回结果)
- 数据库存储采用mysql(写入QPS 2048/s)
- 机器是4核8G. 最多支持开8个进程,每个进程可以支持开256个协程。即一台机器的最大并发是(8*256=2048/s)(这个已经算很高了)
- 需要采集10亿个网页数据
- 爬虫执行的任务都是去重后的(去重也是一门学问,后面细聊,本篇不作为重点)
- 不使用代理也不会被风控掉
最原始的爬虫架构(单线程)

- 目前看1/s,一个小时也就采集了3600个网页,对于我们实际需要的10亿条,大概也就跑个760+年吧。看来这个可以做为老祖宗的遗产了。
疯狂的多进程+协程
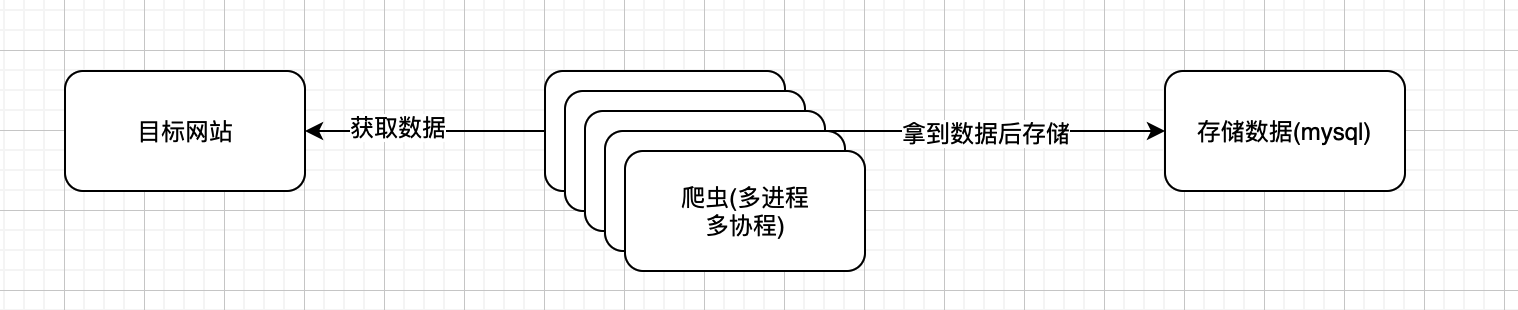
- 这次我们直接放了大招。直接在一台机器上开了多进程+多协程。我们现在的抓取速度是(8*256=2048/s), 正好是mysql的写入qps,勉强可以。那我们需要多少135天。基本4个月. 怕是跑完之后公司就gg了。
我想飞起来
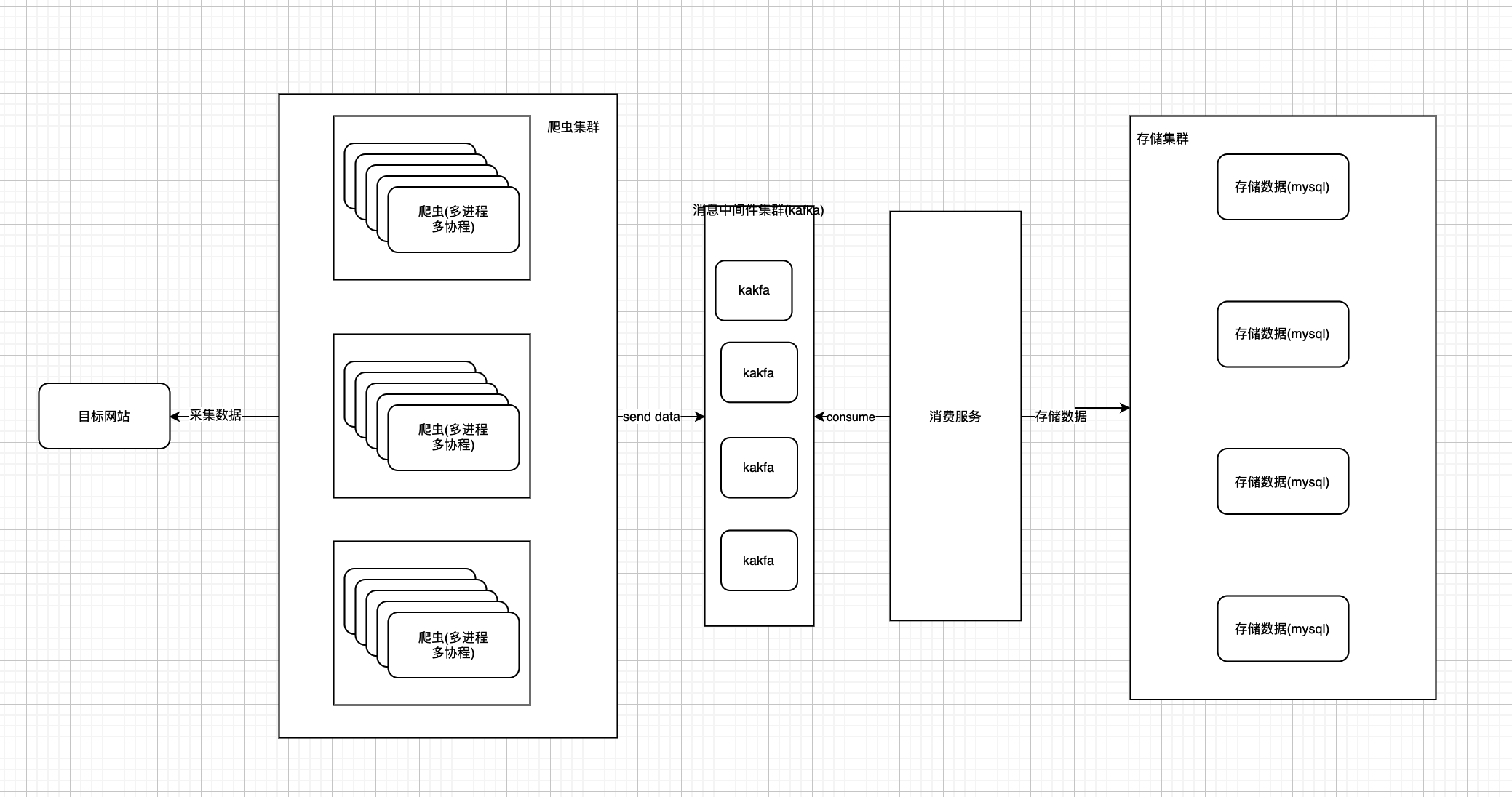
- 上面就是 加了3台机器( 我们现在需要大概1个多月(前提是入库的速度与抓取的速度是一致的,不存在消息堆积),也可以再加机器,加个100台,2天就给你跑完(这只是假设的场景))。
- 上面还多了三个东西。
- 消息中间件集群(一般kafka即可)
- 消费者服务
- 存储服务集群。
- 因为单个mysql的Qps就是2048. 如果并发量再多,mysql就直接炸掉,就算抓取到了数据,数据没有保存起来也是白搭。所以一般就是采用消息中间件,作为临时缓冲,然后搭建分布式存储集群(分库分表),以保证能够及时存储。
来个小总结
- 看了上面的,这不就是同时请求的并发数目,加机器其实也算提高并发数。对,高并发对于矛(爬虫)来讲其实就是,疯狂的加并发。
别慌,坑多着呢。(基本就是爬虫工程师常遇到的问题,等我有时间来填)
- 我们上面讲的是只是理想情况下。现实很残酷的。一个能够高并发分布式的爬虫系统,大概率是会遇到下面的问题:
- 服务端有风控(风控又是很多种)
- js混淆(有时候难到你怀疑人生)
- token鉴权
- 验证码验证
- 同一Ip请求次数限制(换ip即可)
- 页面定时改版
- 还有其他类型的(参考大厂)
- url去重
- 脏数据清理
- 服务端不行(解决了其他的问题之后的瓶颈)(比如某些渣的网站,QPS就那么多,稍微高点并发,直接服务端500,或者官网直接挂掉)
- …
- 服务端有风控(风控又是很多种)
最后的总结
- 对于矛方的高并发,最核心的其实还是在与服务端的响应瓶颈。所以如果做好一个高并发的盾方才是难度最高的。