通过本篇,你可以了解到RabbitMQ以及Kafka是如何保证消息队列高可用的
如何保证消息队列高可用
- 在上一篇 我们聊到使用消息队列,会降低系统可用性(简单来讲,MQ挂掉了怎么办)
- 不同的MQ对于高可用有不同的措施,面试问,也是回答自己用到哪些MQ,分别介绍相应的高可用措施是什么。
RabbitMQ
- RabbitMQ 是基于主从(非分布式)做高可用的
- RabbitMQ分为三种模式。
单机模式(无高可用性)
- 基本就是自己玩玩
普通集群模式(无高可用性)
- 普通集群模式就是启动多个RabbitMQ实例,这个MQ之间互相同步meta信息(可以理解为queue的一些配置信息,通过meta信息,可以找到queue所在的实例)。消费的时候,如果queue所在的实例与连接的实例不是一个,连接的实例将会从实际queue所在实例,拉取数据。
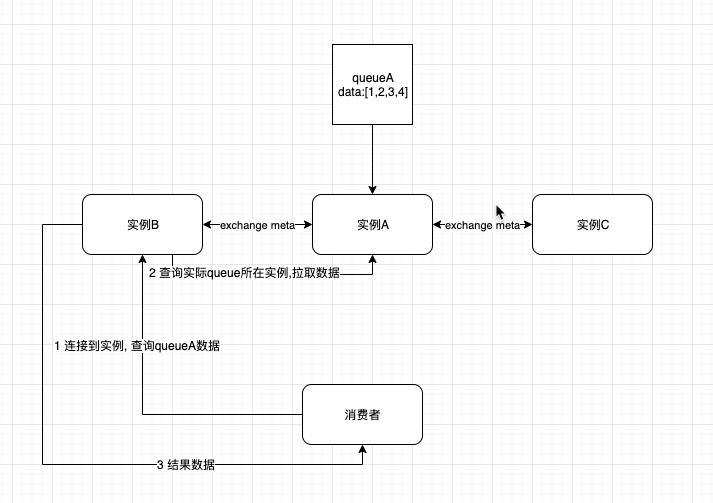
- 很明显的这种方式有几个弊端
- 随机选择一个实例,会有拉取数据的开销
- 如果固定选择一个实例,会有单例性能瓶颈
- 如果存放数据的实例宕机了,会导致其他无法获取到数据。当然也可以开启消息持久化,理论上数据不会丢,但是其他实例还是要等恢复了之后才可以拿到数据.
- 所以这个普通模式其实提高吞吐量,多个节点集中读取某个queue的数据.
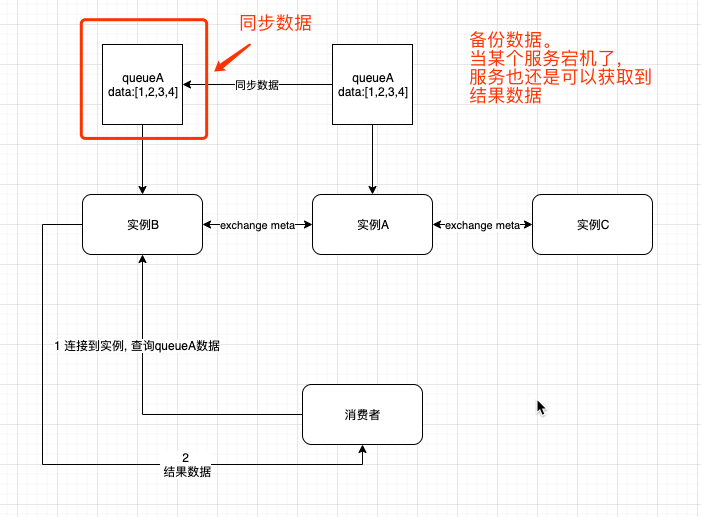
镜像集群模式(高可用性)
- 镜像集群模式,简单说,就是queue的数据不是像普通集群模式,实际上只有一个queue保存数据。而且部分实例上有queue的备份。这样即使某个实例宕机掉了,服务也还是正常的。
- 弊端
- 每个queue都会备份到部分实例,如果实例很大,那么磁盘,性能(备份数据,带宽和内存都负载很重)。
- 这种不是分布式的,不存在扩展。例如某个queue的数据很多,新增机器其实也是需要备份所有的数据,根本解决不了负载的问题。
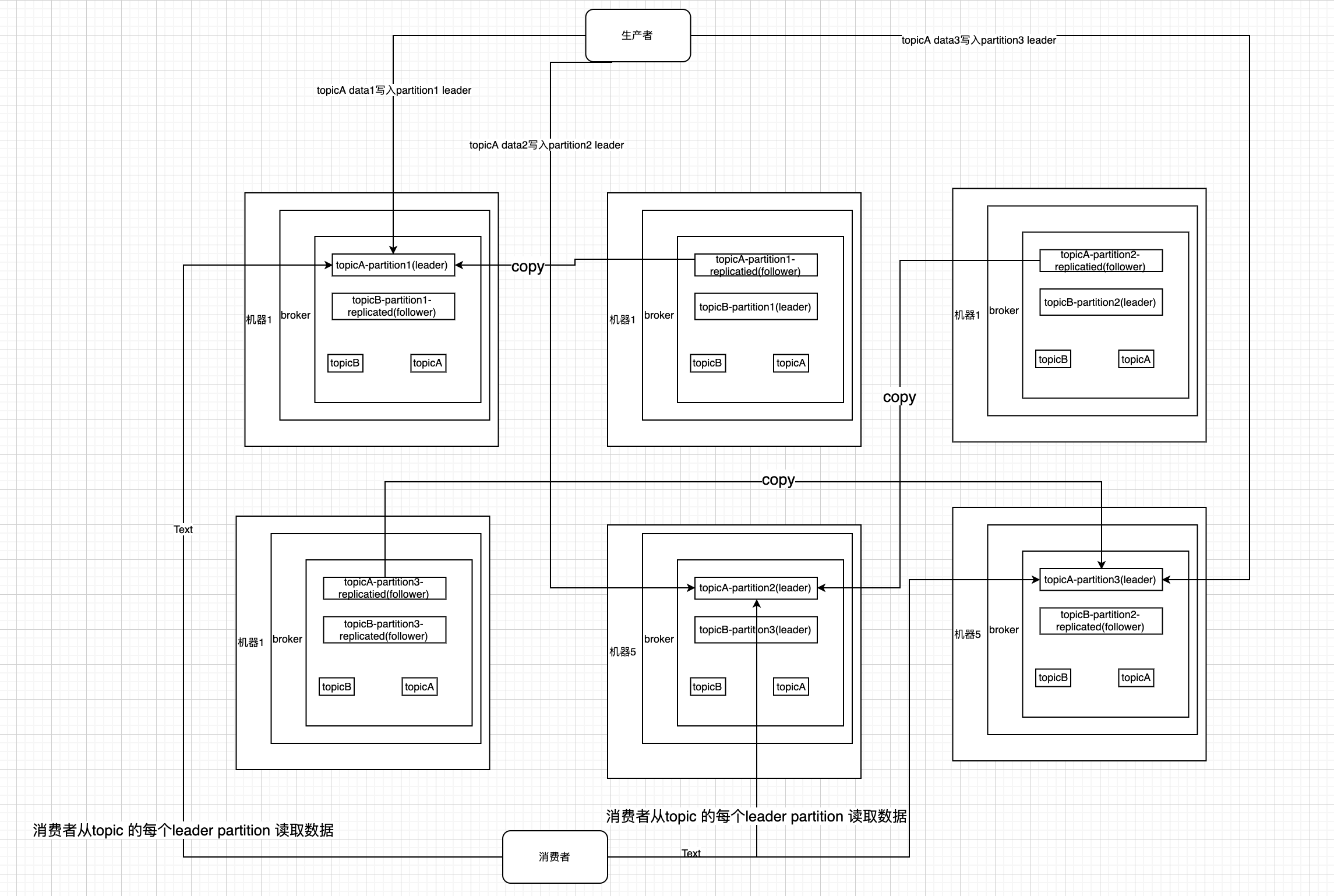
Kafka
kafka是基于副本机制来做高可用的
kafka基本架构
- 由多个broker组成(节点)
- topic是由多个partition组成的
- 每个partition可以放在不同的broker上,每个partition只存储部分数据
- 每个partition 在其他节点上会有自己的副本。相同partition会选举出一个leader节点,所有的数据都会通过leader读写
所以kafka的高可用机制是: 不同的partition有不同的备份,如果某一台机器宕机了,没关系,还有备份,如果这个机器上的partition是leader,那么剩余的partition重新选举出新leader,由新leader进行数据更新.
kafka与RabbitMQ还有一点就是,kafka的数据是真正的分布式,即部分数据在其他节点上。RabbitMQ镜像模式其实还是所有数据都是在一个节点上,其他节点都是所有数据的备份。
kafka详细剖析,待有时间补坑