通过本文你可以了解到:
0 为什么要使用消息队列(MQ)
1 消息队列 优缺点
2 消息队列 市场上现有MQ分析
为什么要使用消息队列
- 用消息队列的场景有很多,但是核心点有三个:解耦,削峰,异步
解耦
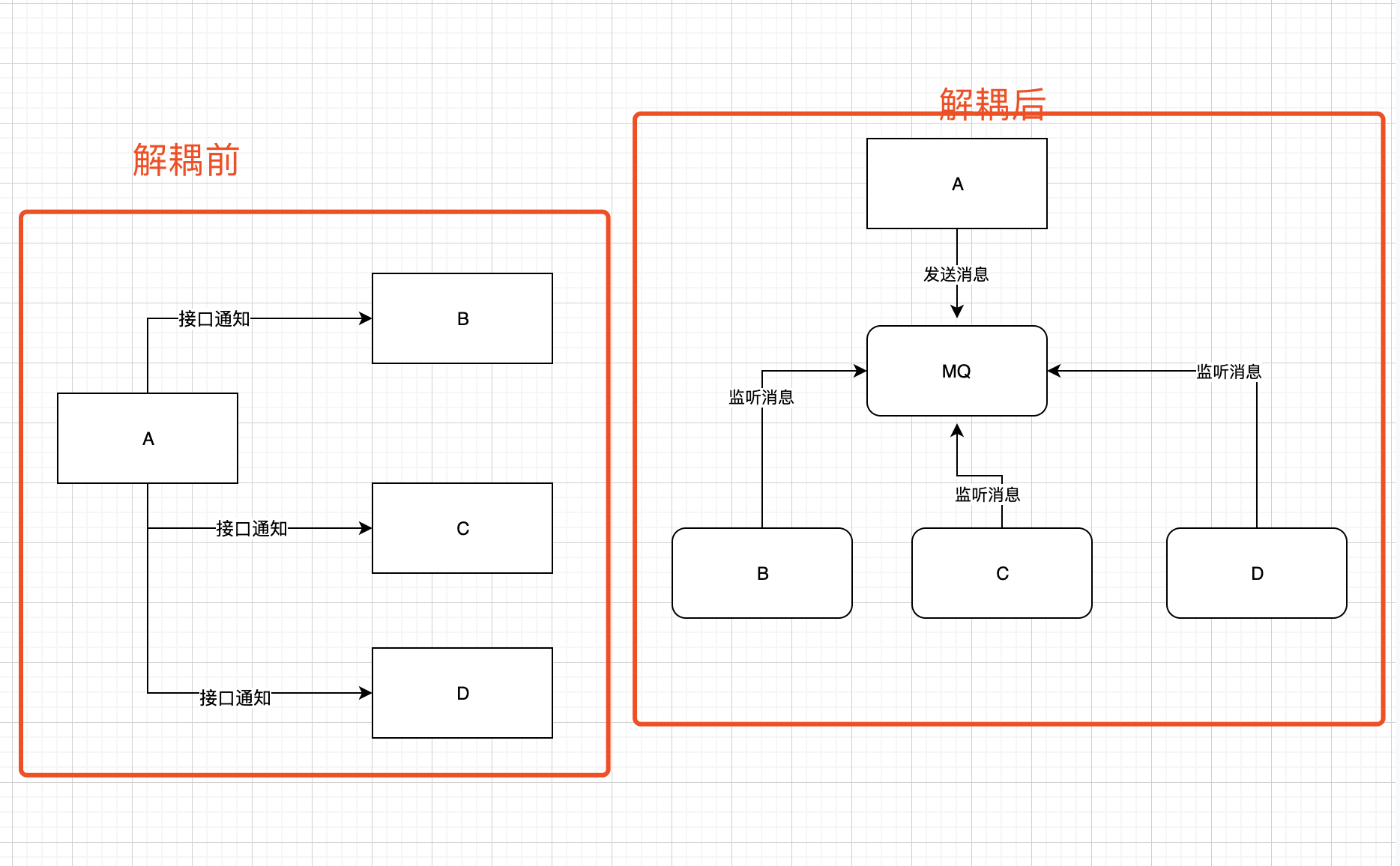
- 考虑下一个场景,有三个系统,A系统完成之后,需要同步结果给B,C系统。后续系统变动,又需要多通知一个D。那么A系统就需要在原来的代码上更改下。再考虑后面C不需要了,A还要去掉。A系统负责人怕是头发全掉了。
- 上面的场景其实就是A系统与其他系统太过耦合了
- 这个时候MQ可以很好的解决这种场景了。A系统完成之后,向MQ发送一个消息,后续那个系统需要,那个系统就去MQ取消息。这样A系统只需要关系自己有没有发送MQ消息,其他系统只需要关系MQ有没有消息。这样就很好的解耦了。
异步
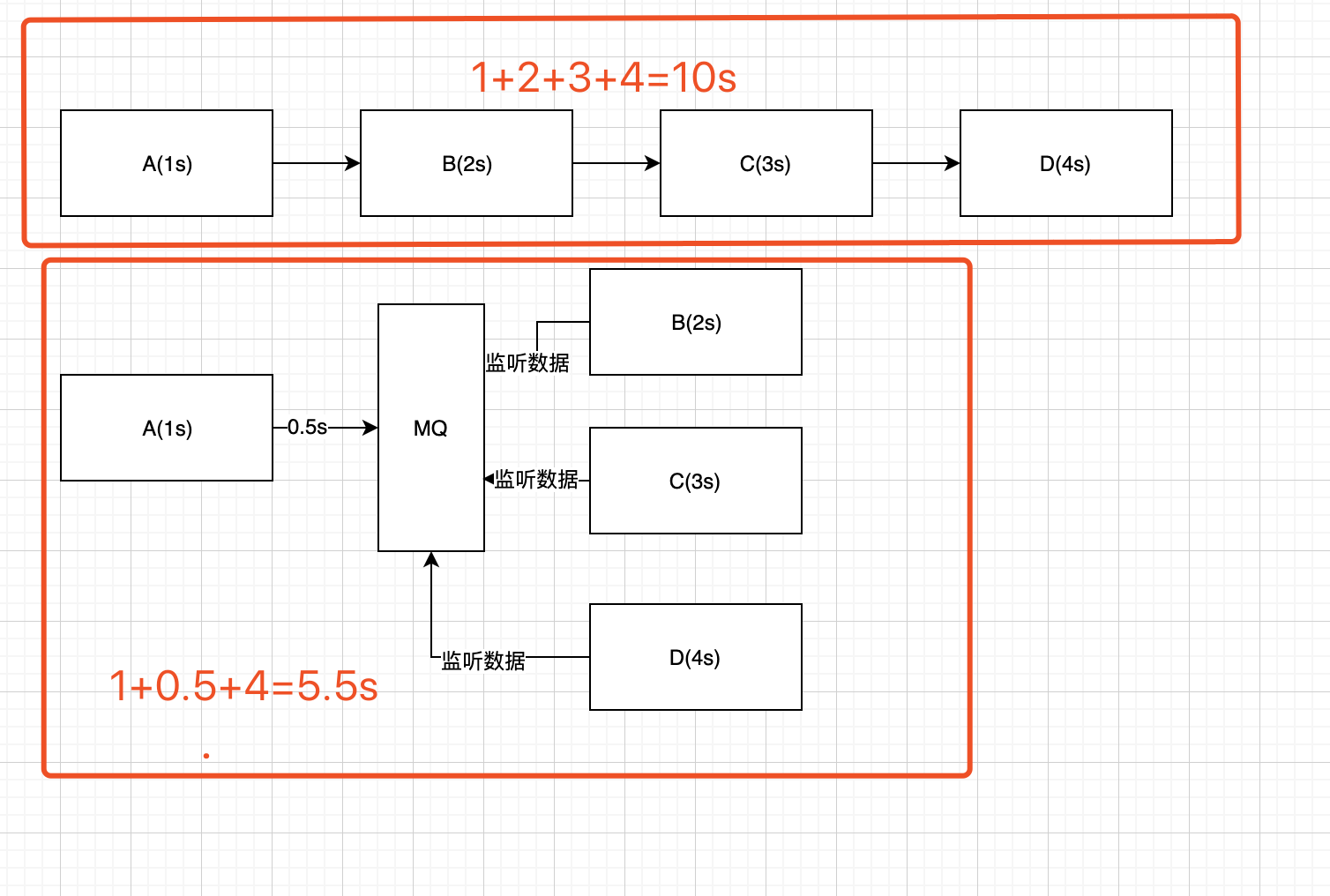
- 用户点击某个操作A时,服务器端需要做一些列(BCD)操作。其执行顺序就是A(1s)->B(2s)->C(3s)->D(4s).链路长,耗时就很长。用户点击了某个操作,需要等待10s,用户怕是直接走了。
- 上面的场景其实就是常见的异步场景。
- MQ这个时候也可以用上。A操作后,发送3个消息出来。BCD通过监听MQ拿到消息,计算。其执行顺就是A->MQ-(BCD). 用时其实就是:A(1s)+MQ(0.5s)+BCD(用时最长的那个4s)=5.5s 比原来的用时,提高了接近一半。
削峰
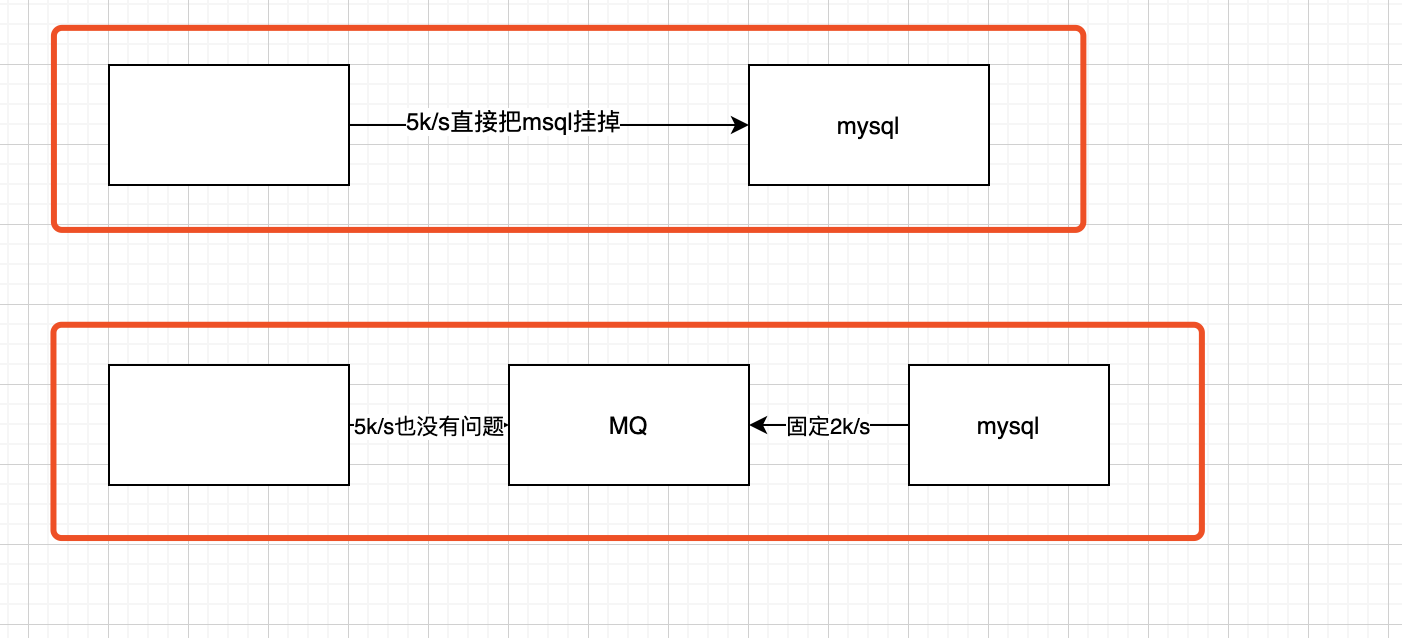
- 考虑一个场景:线上生产会收集用户点击的日志,而这些日志全部都是由mysql存储的。一般mysql可以2k/s, 如果是5k,基本上就是要被打挂了。
- 上面的场景其实就是峰值过高,导致其他系统处理不过来,直接崩。
- 解决上面的方法有很多,mysql分表分库,考虑其他数据库。用MQ也可以解决。日志都先扔到MQ中,起一个服务专门消费日志MQ消息(消费频率是2k/s)。就算是后面每秒发送5k,消费频率也不会边,自然而然mysql就不会挂了。
MQ的优缺点
- 优点上面就已经描述了。下面聊聊缺点
缺点
- 降低系统可用性
- 原来只有4个系统,现在又多了一个MQ,而且又是核心中间件,万一MQ挂了怎么办!!
- 增加系统复杂度
- 消息有没有重复消费,消息丢失
- 结果一致性
- 一部分消费MQ成功,一部分消费失败,数据就不一致了。就需要解决这个一致性
上面前两个点,其实就是分别对应MQ的高可用性,ack机制
- 一部分消费MQ成功,一部分消费失败,数据就不一致了。就需要解决这个一致性
市面上常用的MQ比较
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 同 ActiveMQ | 10 万级,支撑高吞吐 | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic 数量对吞吐量的影响 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同 ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失 | 同 RocketMQ |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 |
参考大佬
为什么使用消息队列?消息队列有什么优点和缺点?Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么优点和缺点?