通过前几篇Flink 实战的文章,应该对Flink有点印象了。接下来,本片文章就简单从基本概念,场景, 架构, 特点等方面介绍下Flink.
什么是Flink
官网介绍如下
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.个人理解
Flink 是一个框架和分布式处理引擎,可以对无界或有界数据流进行状态计算。注意加粗的几个字是核心。下面会聊到。
能够解决什么问题
- 通用处理流/批处理。
适用场景
- 实时智能推荐
- 复杂事件处理
- 实时数仓与ETL
- 流数据分析
- 实时报表分析
基本的概念
流/批处理处理思想
- Flink对于批处理认为是有界的流处理。而Spark则认为流处理是更快的批处理。那个更有优势不重要,符合自己的需求并扩展性良好即可。
流 stream
- 有界流(批处理)vs 无界流(流处理)
- 有界流:一批连续的数据有开始有结束。(几何中的段的概念)
- 无界流:连续且无边界的数据流。(几何中射线的概念)
- 实时流和record Stream
- 实时流:举例天猫双十一大盘
- record Stream: 离线数据清洗。
- 有界流(批处理)vs 无界流(流处理)
状态 state
- 状态可以简单理解为在处理数据的过程中,每个数据的改变都是状态的改变。
时间 time
- Event time 时间发生的时间
- Process Time 消息被计算处理的时间
- Ingestion Time 摄取时间:事件进入流处理系统的时间。
架构
组件结构 参考
- API&&组件库层
- Flink 同时提供了高级的流处理API(eg flatmap filter等),以及相对低级的processFunction. 在API的基础上,抽象除了不同场景下的组件库(FlinkML(机器学习),CEP(复杂事件处理)等)
- Runtime层
- 是Flink的核心层。支持分布式作业的执行,任务调度等。
- Deploy 层
- 部署相关。支持 local, yarn ,cloud等运行环境。
- 注意
- FLink组件库调用API(StreamAPI或者是DataSetAPI), API(StreamAPI或者是DataSetAPI) 生成jobGraph,并传递给Runtime层,jobGraph 根据不同的部署环境,采用不同的配置项(Flink内置的)执行。
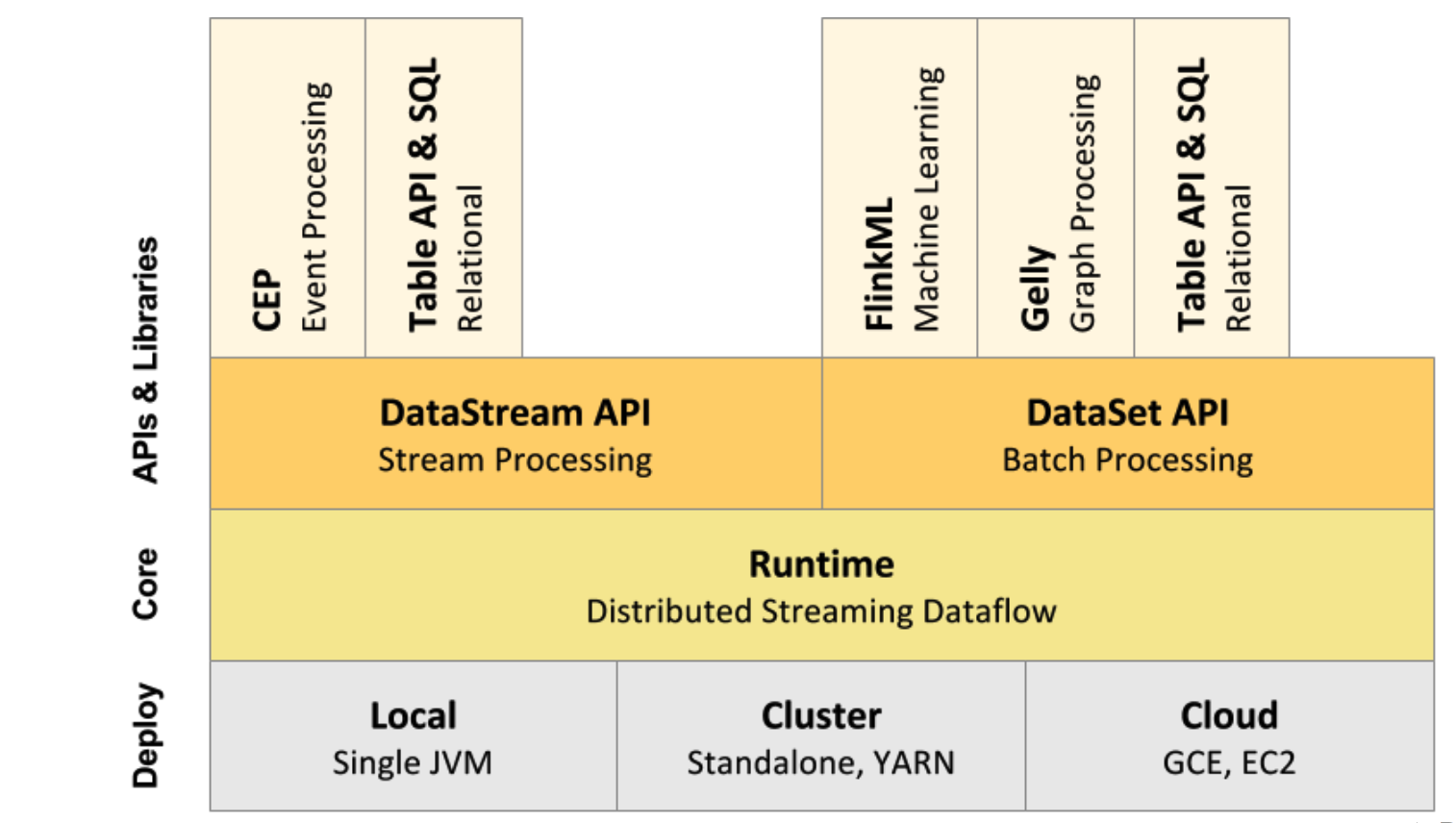
- API&&组件库层
Flink 集群运行时架构 参考
- jobManagers(master) 负责 (至少有一个)
- 协调分布式执行
- 任务调度
- 协调检查
- 协调错误恢复
- taskManagers(slave) 负责 (至少有一个)
- 执行数据流任务
- 缓存并交换流数据
- client 作为数据源的输入,输入之后,可以被清除,也可以或者是处理其他的任务。
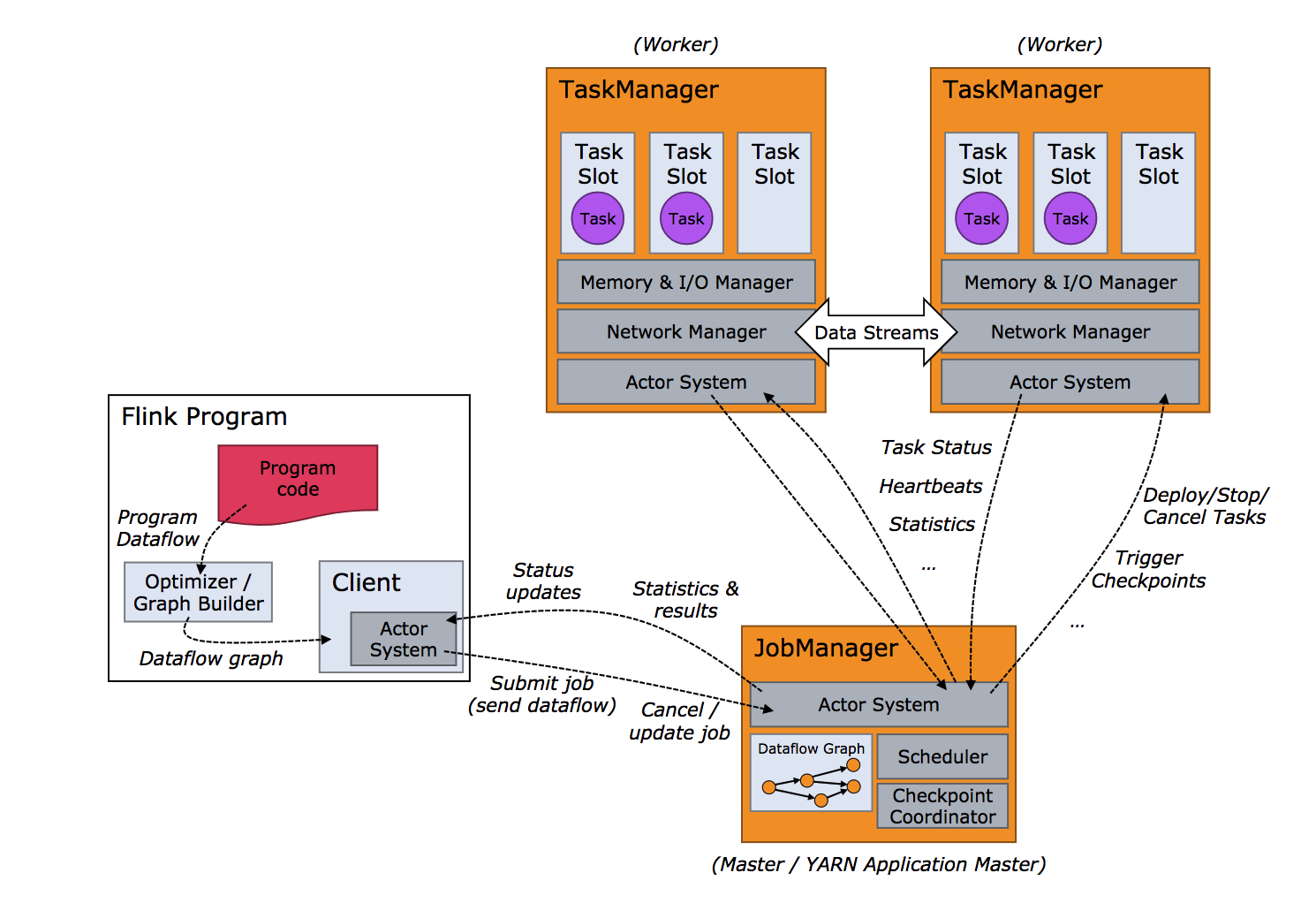
- jobManagers(master) 负责 (至少有一个)
特性
- 流处理
- 支持高吞吐,低延迟,高性能流处理操作
- 支持高度灵活窗口(slideWindow SessionWindow等)
- 支持状态计算,同时具有exactly-once特性
- 支持 batch on stream
- API
- StreamAPI
- BatchAPI
- 众多Libraries
- 机器学习
- 图处理
- 。。。
总结
Flink 本质上还是只是一个专门解决流批数据处理的框架,并且在性能,稳定,开发,部署等方面具有独到之处。如果我们日常需求中有涉及到大数据处理,且很可能会涉及到协同分布式等,Flink是一个很好的选择。